
TL;DR: The ability to feed AIs large bodies of knowledge is a game-changer that promises to reduce hallucinations and allow the automation of many more processes. Ops leaders should start asking their teams critical questions about documentation, knowledge repositories, and process design.
A few days ago, OpenAI released a major update to a somewhat less-known offering, i.e., its “Assistant” API. This is significant.
In a nutshell, Assistants (also called “Agents” in some of the hyperlinks, an interesting fact), are instances of GPT that can call external services and rely on uploadable bodies of knowledge to draw from when conversing with users. OpenAI massively expanded the possible size of these libraries, going from 20 documents to 10,000.
Why does it matter?
Let’s think about what makes for exciting optics in AI, vs. what creates scalable value. Here’s a framework that could be useful (it’s a 2x2, because once a consultant, always a consultant).
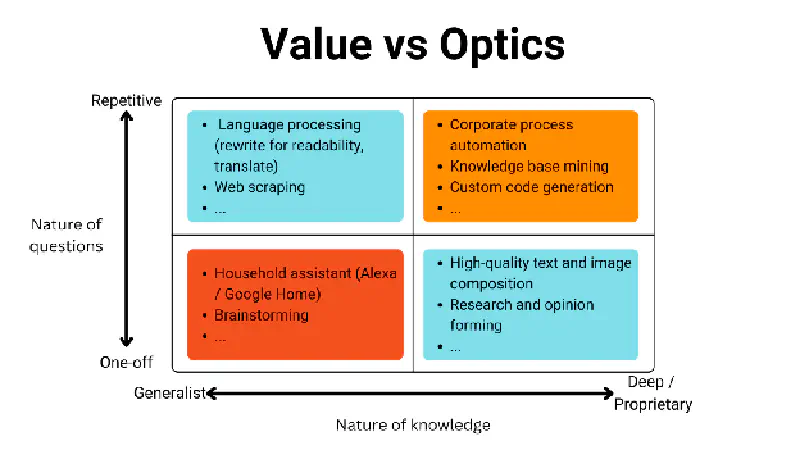
What drives optics and controversy is often what is in the bottom row. What is more intriguing for a newspaper to report on—a company using AI to organize and catalog expense reports; technology that generates lifelike faces; or the struggles of a journalist attempting to use a virtual assistant?
However, most of the value created by AI will be in work rooted in the top right quadrant of this 2x2. Those are repeatable processes, where:
- Quality metrics can be developed and tracked;
- Tasks can be isolated and defined; and where
- it’s easier for executives to make a financial case for investments in efficiency and scalability.
Critically, these are also processes where specific, often confidential knowledge is required, and factual correctness is key. And we know that factual correctness isn’t exactly the strongest suit for an LLM as people are finding out time and time again.
Enter RAG

… that is, “Retrieval Augmented Generation”. This is a version of the technology powering perplexity.ai, a unicorn that focuses on providing accurate answers to user questions, based on sources it finds on the web (and no, that’s not what ChatGPT does on its own).
RAG is based on a simple idea: given a library of knowledge, use your AI to quickly identify relevant pieces of it (many techniques do this efficiently, such as vector encoding and keyword searches, but that’s for another day); then use the LLM engine to inform the answers, significantly lowering the hallucination rate. Essentially, it’s like an open-book vs. a closed-book test.
And this is why OpenAI’s new feature is a game-changer. Until now, GPT assistants (i.e., custom, proprietary versions of ChatGPT) could only access up to 20 documents simultaneously. From now on, the limit has been raised to 10,000 documents at a time.
So, now your company could upload HR policies in a GPT and use it to help with expense report validation. Or, you could upload past marketing materials, product specs, and market research, and use a custom GPT to critique or generate drafts of marketing copy. I remember the days when I was overseeing the PRC process in a biotech startup—wouldn’t it have been nice to have a system that would take a first stab at validating whether our label supported each claim?
We should expect a long wave of “hidden automation”. While you’re reading this, your competitors are thinking of ways to share their institutional knowledge with AIs, to automate or support repetitive back-office tasks. Productivity gains will be enormous and widespread.

The best analogy that comes to mind is CNC machines. They don’t replace every step of every manufacturing process; on the contrary, processes are often rebuilt around them.
So what should we do?
Start by asking critical questions about your knowledge and your processes.
-
How is institutional knowledge organized and stored in your company? Don’t just think of process manuals: email threads, Slack texts—this all adds up to descriptions of how processes work. AIs can manage formal as well as informal documents.
-
What kinds of errors can you tolerate in your processes? Don’t say “none”. Human beings make mistakes all the time: we arrange work in such a way as to catch (most of) them. We hire people because, despite their fallibility, they help. The same goes for AI.
-
How can you design your processes for better automation? Think broadly: AIs don’t need forms as inputs. Emails, free text, etc—these can be perfectly acceptable inputs for an LLM.
-
How will you define and measure success? Leadership teams are asking for more efficiency—how can you demonstrate it? What hard metrics would you like to improve?
PS: Yes, Big Tech is investing heavily in developing personal assistants and chatbots geared at consumers—but this appears to be aimed at driving utilization of other ecosystem tools, not at offering a stand-alone, profitable product.
Originally published on LinkedIn in April 2024.